
2021-05-22
The constant pursuit of artificial intelligence (AI) algorithms with higher performance-to-power ratios has promoted the development of specific hardware design technologies, including memory computing for system-on-chip (SoC) design. In the beginning, memory computing mainly appeared publicly in semiconductor start-ups hoping to subvert the status quo of the industry, but now, many industry leaders are also beginning to use memory computing technology at the bottom.
Innovative designs using in-memory computing will subvert the AI SoC landscape. First, let's take a look at the status quo of AI SoC that startups intend to use in-memory computing to disrupt. Since 2015, many companies and venture capital have begun to invest heavily in new SoCs dedicated to AI, prompting a huge leap in AI hardware. In the last 5 years, investment has accelerated, which has driven industry leaders to make many improvements in AI hardware design. Intel's x86 processor adds new instructions and even adds a separate NPU engine. Nvidia added a specific Tensor core, abandoned GDDR, and implemented HBM technology to increase memory bandwidth. Google has developed a specific ASIC TPU (Tensor Processing Unit, Figure 1) dedicated to AI algorithms. However, even if these structures continue to improve, investors still hope that start-ups can develop disruptive AI technologies.
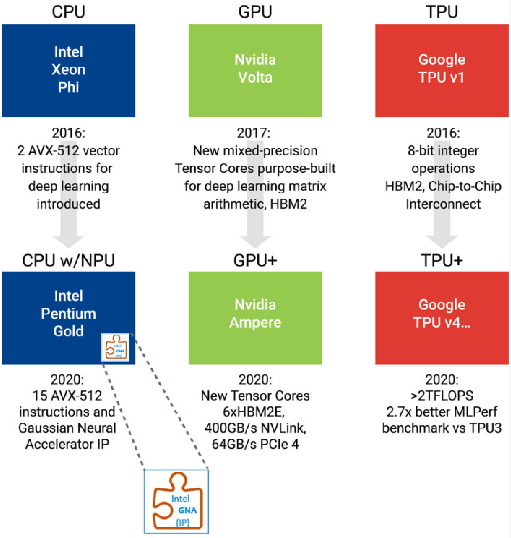
Figure 1: Intel, Nvidia, and Google are introducing new hardware architectures to improve the performance-to-power ratio of AI applications
Why is the disruption of AI computing so interesting?
The three main reasons for investing heavily in AI hardware are as follows: 1) The amount of data generated is increasing exponentially, and AI is a key technology to solve the complexity problem; 2) The power consumption of running AI algorithms using existing architectures (especially at the edge) And the time cost is still too high; 3) The parallelization of AI computing engines has reached the limit of chip size, prompting these systems to expand into multiple chips, and this expansion is only practical in the field of cloud or edge cloud data centers.
Together, these new challenges have driven designers to continuously explore new and innovative hardware architectures. In-memory computing is regarded as one of the most promising hardware innovations because it can provide many orders of magnitude improvement.
AI computing disruptive path
Start-ups and leading semiconductor suppliers are looking for potential ways to accelerate AI computing.
New AI model: New neural networks are frequently introduced. For example, Google's large research team focused on publishing models launched EfficiencyNet. Advanced Brain Research released LMU, and Lightelligence cooperated with the Massachusetts Institute of Technology to run the Efficient Unitary Neural Network (EUNN).
Integrated photonics: Some start-up companies are developing new integrated photonics technology as another way to disrupt.
Compression, trimming, and other technologies: Use compression, trimming, and other technologies to allow specific AI functions to run on small and efficient processors, such as DesignWare® ARC® EM processor IP that runs at frequencies below 100MHz.
Expansion of the computing system: The industry leader has already fully produced solutions to expand the computing system through multiple chips, motherboards or systems to meet the most complex and cost-intensive challenges of AI.
Companies are seeking or have implemented these ways to improve performance. Memory computing design can be built on the basis of these methods, through multiple improvements, and other development techniques to improve efficiency.
What is in-memory computing?
Memory computing is a way of designing memory next to or inside hardware processing components. In-memory calculations will use register files, memory in the processor, or will convert SRAM or arrays of new memory technologies into register files or the calculation engine itself. For semiconductors, the basic elements of memory computing may significantly reduce AI costs, shorten computing time and reduce power consumption.
Software and hardware for memory computing
In-memory computing has both hardware and software elements, which may cause some confusion. From a software perspective, in-memory computing refers to processing analysis that runs in local storage. In fact, the software makes full use of the memory that is closer to the calculation. "Memory" may be a bit vague from a hardware point of view. It can refer to DRAM, SRAM, NAND flash memory and other types of memory in the local system, rather than the memory that obtains data through a networked software infrastructure. Optimizing software to utilize more local memory presents huge opportunities for industry advancement, and the engineering team will need to continue to focus on these innovations at the system level. However, as far as hardware optimization is concerned, memory computing provides bit-level innovation, which can simulate the human brain more realistically, and the efficiency is more than 1,000 times that of current computing.
In-memory computing, near-memory computing and analog computing
In-memory computing is not only a magical solution to AI algorithms, it has achieved various implementations, and it is still being developed through gradual innovation. Register files and caches have been implemented for decades, and recent memory computing is a progress made after implementation improvements, and has been implemented in new SoCs in the past few years.
There are millions of coefficients and multiply accumulations (MAC) required by the AI algorithm, even if there are not billions of them. In order to effectively execute all these MACs, a custom local SRAM for a series of MACs is now designed in the SoC, the sole purpose of which is to perform AI model math, that is, matrix/tensor math. Integrating a dedicated local SRAM for a group of MACs to perform AI model mathematics is the concept of near-memory computing. In near-memory calculations, the local SRAM is optimized to store the weights and activation values required by the specified MAC unit.
In the process of developing memory computing, the next development is naturally analog computing. Simulation calculations can achieve more parallelism, and can simulate the efficiency of the human brain more realistically. The simulation system runs MAC and memory in parallel, and in terms of system efficiency improvement, it even far exceeds the efficiency improvement obtained by only close to the memory calculation method. Traditional SRAM can be used as the basis for the realization of memory simulation calculations. Synopsys has provided customized services for this purpose.
Memory technology solves memory computing challenges
Compared with traditional SRAM, new memory technologies such as MRAM and ReRAM can provide higher density and non-volatility. Improvements in SRAM can increase the utilization of computing and on-chip memory. Utilization is one of the most critical design challenges facing AI SoC designers (Figure 2). SoC designers need to design memory subsystems specifically for AI data movement and computing (regardless of the technology used).
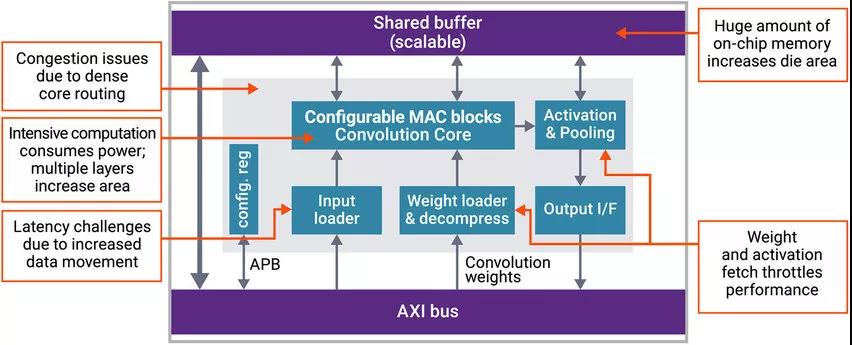
Figure 2: AI SoC has extremely intensive calculation and data movement, which affects latency, area, and performance
The key challenge for AI SoC design with memory system is related to the number of MACs and coefficients that need to be stored. For ResNet-50, a weight of more than 23M is required, which can be calculated as 3.5 billion MAC and 105B memory access. Not all processing runs at the same time, so the size of the maximum activation value may be the key bottleneck of the memory subsystem. Control engineers know that bottleneck design is the most expensive function to perform, thereby increasing efficiency. Therefore, the design needs to ensure that its memory computing architecture can effectively handle the largest activation coefficient layer.
Meeting these requirements requires a large amount of on-chip memory and multiple layers of intensive computing. Unique techniques for memory design are currently being developed to reduce latency, coefficient volume, and the amount of data that must be processed around the SoC.
DesignWare IP solution for memory computing
Synopsys provides customers with a wide range of IP options for in-memory computing. Memory compilers optimized for density or leakage power are used to develop local SRAM for near-memory implementations, and sometimes such implementations can instantiate more than 1,000 MACs. MAC can use a set of primitive mathematical functions of Synopsys' basic core, including flexible functions such as dot product (a common AI function).
In addition, Synopsys DesignWare multi-port memory IP supports up to 8 inputs or 8 outputs, which improves the parallelism within the computing architecture. As AI becomes more common, multi-port memory becomes more common in designs.
Synopsys has developed a patented circuit that specifically supports memory computing innovation. The Word All Zero function shown in Figure 3 basically eliminates the zeros to be processed. Why move the multiplier to zero? The Word All Zero function significantly reduces the amount of calculation required and can reduce the power consumption of data movement within the chip by more than 60%.
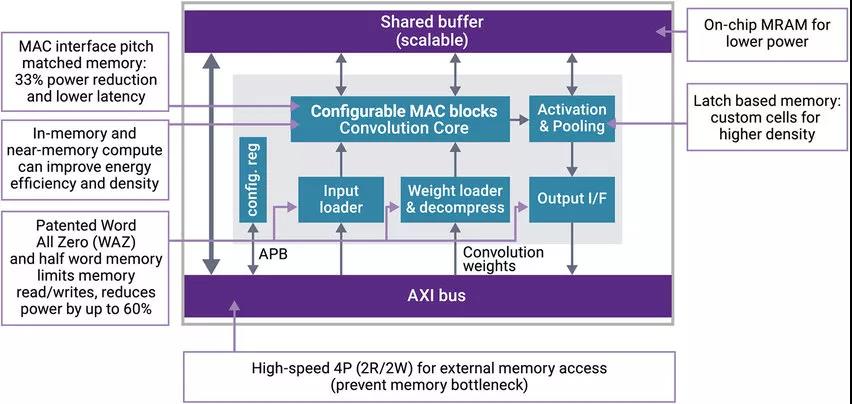
Figure 3: In addition to the Word All Zero function, Synopsys DesignWare embedded memory IP also provides a variety of features to solve power consumption, area and latency challenges
Conclusion
At present, the speed of using memory computing in the industry remains to be further observed. However, the prospect of this technology, as well as the concept and practice brought by new memory, innovative circuits and creative designers, will surely become an engineering feat. In many cases, the process of developing a solution is as interesting as the final result obtained.






